
はじめに
AWS Ambassadors 2年目、インフラエンジニアの安斎です。
昨年に引き続きラスベガスで開催されている「AWS re:Invent 2023」に参加しています。
昨年はブレイクアウトセッションをレポートしました。今年はインフラエンジニアとして注目したSAPシステムの障害時の運用に関するワークショップについてレポートします。

ワークショップ概要
・タイトル:Build resilient SAP systems(弾力性のあるSAPシステムを構築する)
・概要:
AWS上にWell-Architected Frameworkに則って構築されたSAP基幹システムに対してAWS FIS(Fault Injection Simulator)を利用して障害を起こし、そのシステムが自力で障害から回復できる(レジリエンスのある)システム構成となっているかを確認する
ラボは3部構成で提供されます。
・ラボ1.1 Amazon EC2の偶発的なシャットダウン
・ラボ1.2 オペレーティングシステム(OS)のカーネルクラッシュ
・ラボ1.3 サブネットレベルのネットワーク中断
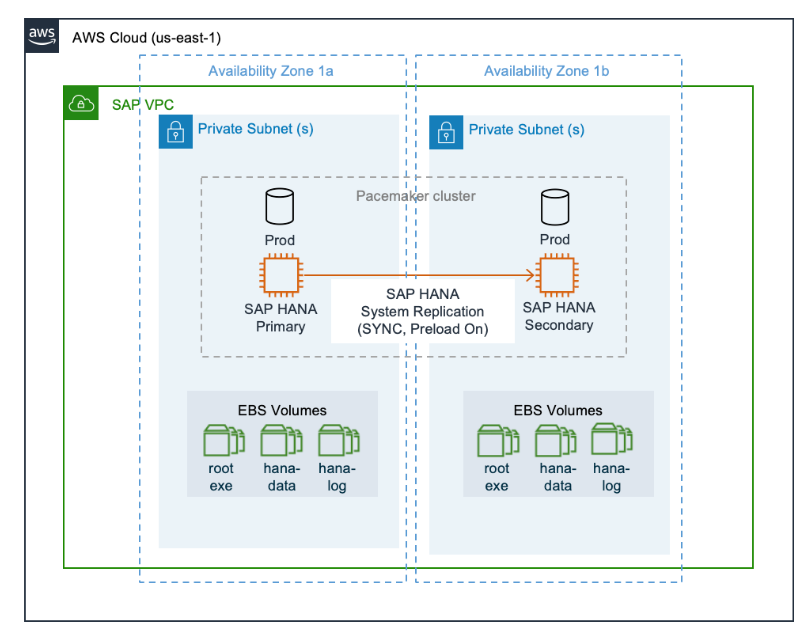
正常な状態
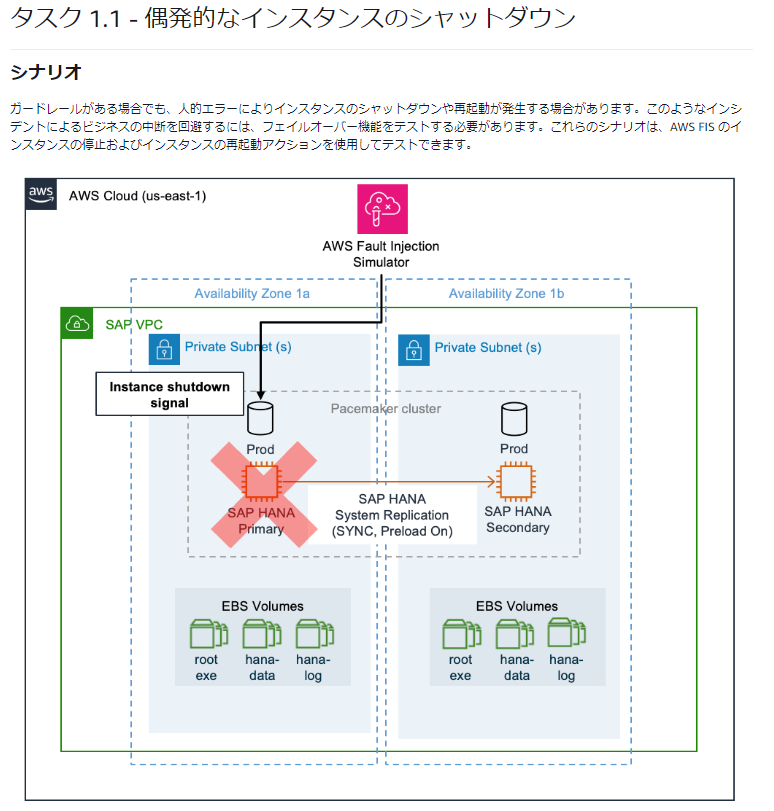
ラボ1.1 Amazon EC2の偶発的なシャットダウン
以下の構成のSAPシステムについて、プライマリのSAP HANAインスタンスをシャットダウンし、セカンダリノードへのフェイルオーバが実施されることを確認します。
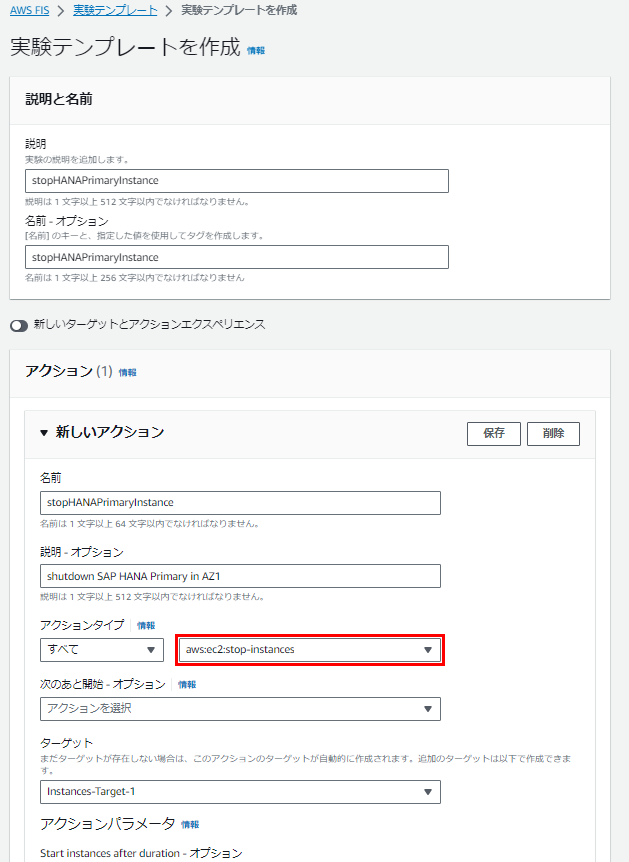
まずこのシナリオで障害を発生させる為に、AWS FISで障害シナリオ(実験テンプレート)を作成します。
ワークショップで設定した内容は以下になります。
アクションタイプを「aws:ec2:stop-instances」としているところが今回のポイントです。
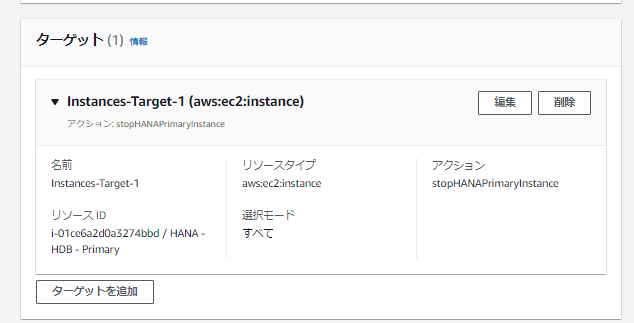
次にこの障害シナリオ(実験テンプレート)の対象となるターゲットを設定します。
今回はプライマリのSAP HANA“prihana”を停止させたいので、プライマリのインスタンスを設定します。
続いて、この障害シナリオ(実験テンプレート)を実行する為のロールを作成します。
ロールは今回のワークショップでは新規作成とし、ロール名はデフォルトで生成されたものを利用します。
パラメータの入力が完了したら実験テンプレートを作成します。
実験テンプレートの作成が完了したら実験を開始します。
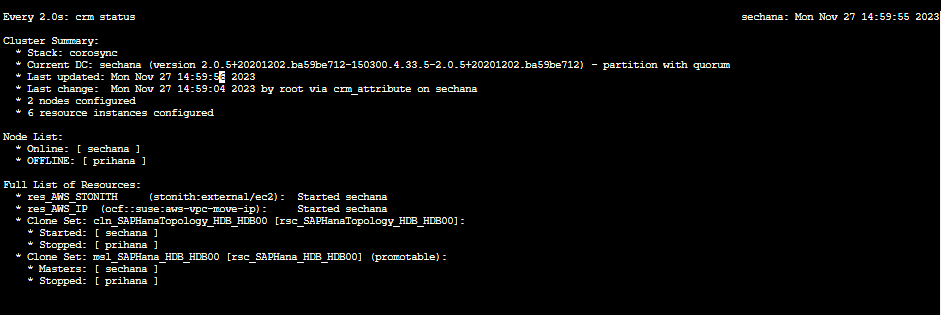
実験が完了したらセカンダリのSAP HANA“sechana”にログインして、クラスターのステータスを確認します。
「Node List」で「sechana」が“Online”、「prihana」が“OFFLINE”となっていることを確認します。
AWSマネジメントコンソールを利用して、実験によって停止したプライマリのEC2インスタンスを起動します。
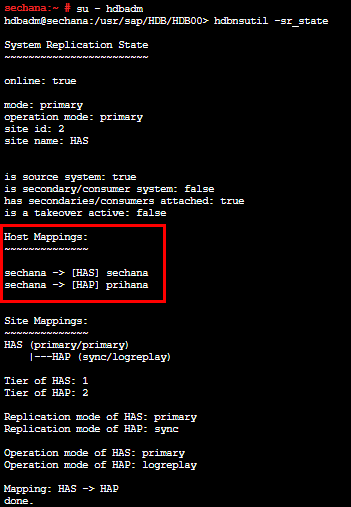
起動後、以下のコマンドを実行し「Host Mappings」で 「HAS」が“sechana”、「HAP」が“prihana”になっていることが確認できれば実験は完了です。
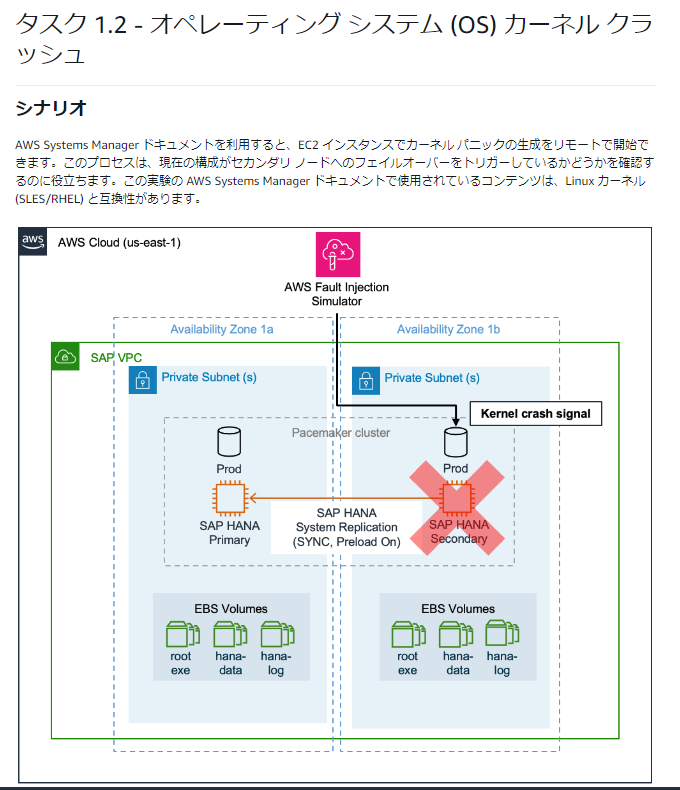
ラボ1.2 オペレーティングシステム(OS)のカーネルクラッシュ
ラボ1.2では、ラボ1.1の障害実験でプライマリとセカンダリが入れ替わったクラスターのうち、セカンダリのEC2に対してカーネルクラッシュを起こし、元々プライマリであったインスタンスをクラスターのプライマリに昇格させます。
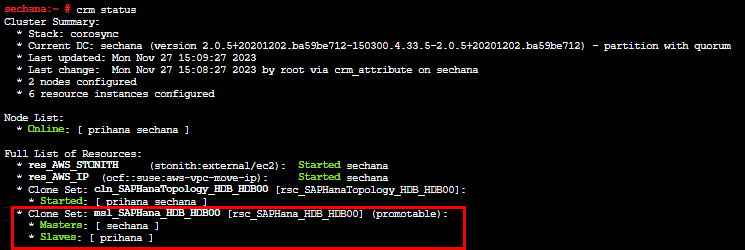
まずセカンダリインスタンスにログインして、プライマリとなっていることをコマンドで確認します。
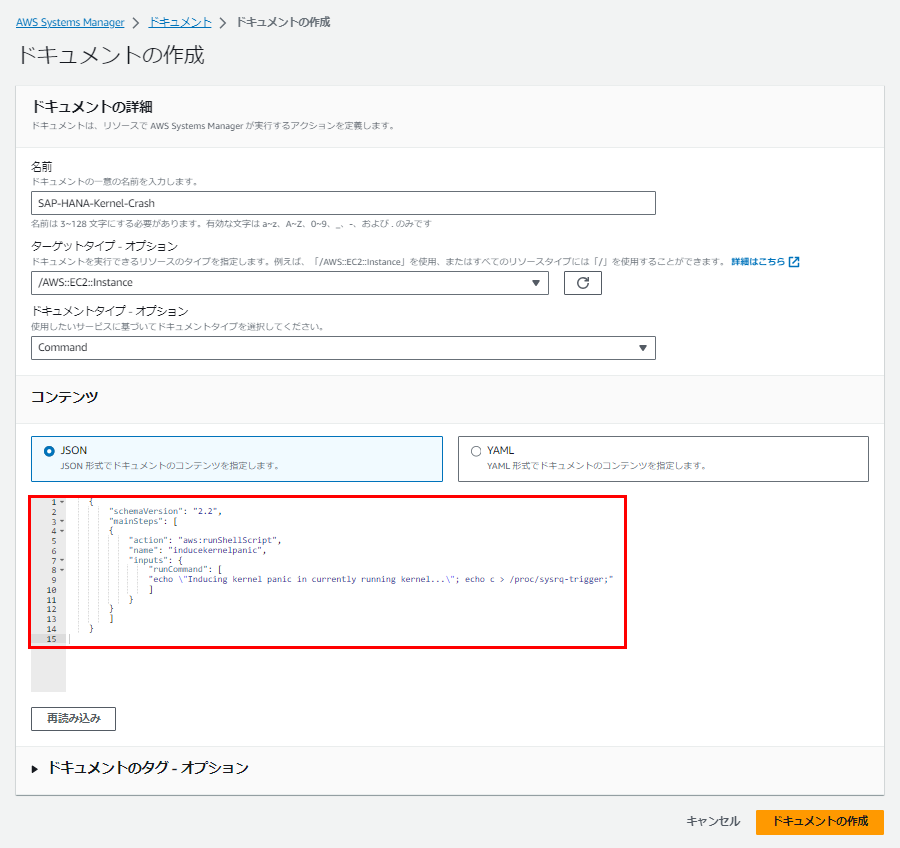
続いてAWS Systems Managerのコンソールに移動し、実行するアクション(ドキュメント)を作成します。
ドキュメントタイプは“Command”、コンテンツで「JSON」を選択し、パラメータを以下の通りに入力します。ポイントはこのコマンドを対象のEC2で実行することです。意図的にカーネルクラッシュを起こさせるように命令しています。
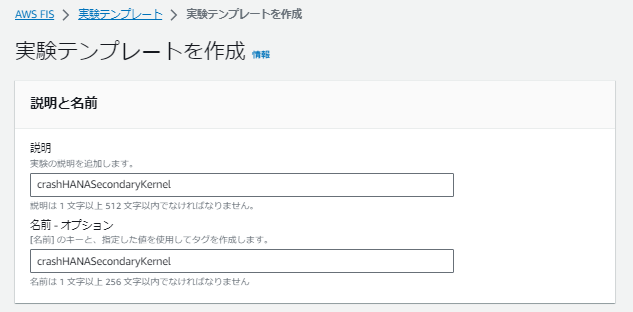
続いてAWS FISのコンソールに移動し、実験テンプレートを作成していきます。
アクションパラメータの「Document ARN」に作成したAWS Systems ManagerのドキュメントのARNを入力します。
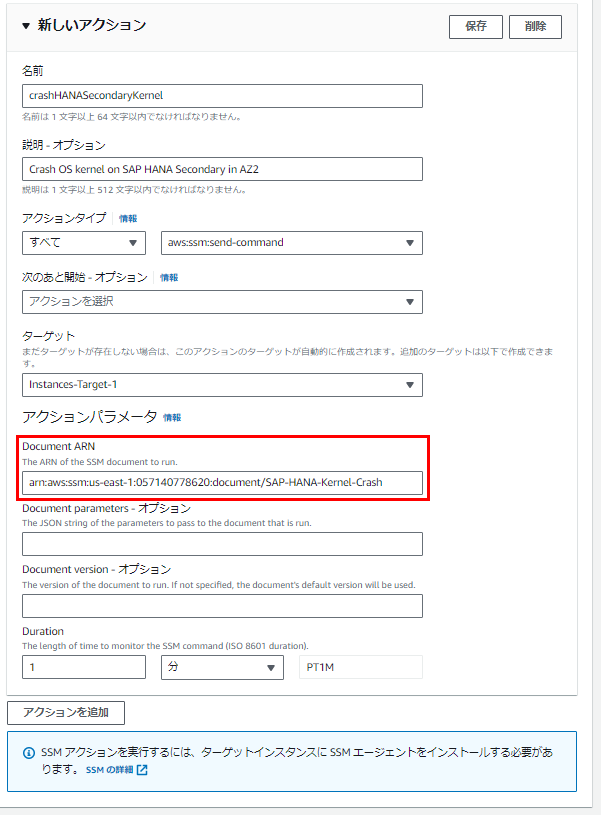
ターゲットにセカンダリのEC2インスタンスを選択します。
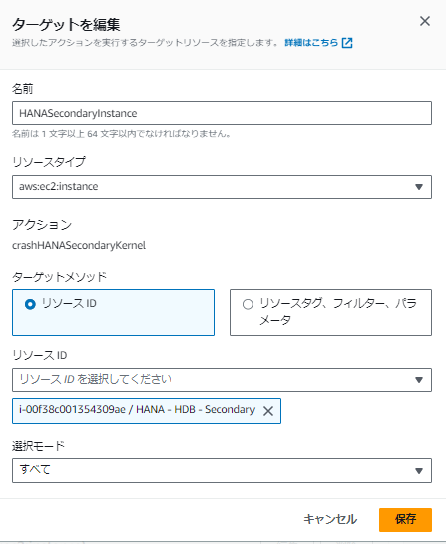
サービスアクセスロールはラボ1.1で実施した内容と同じように新規でデフォルト名称を使用して作成します。
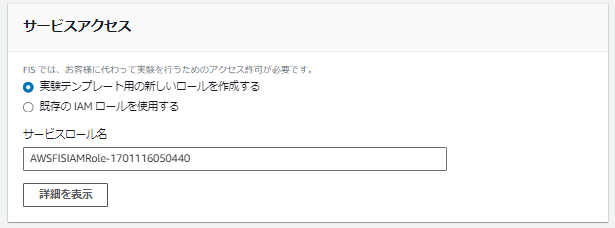
正常にFISの実験テンプレートが作成できたら実験を開始します。
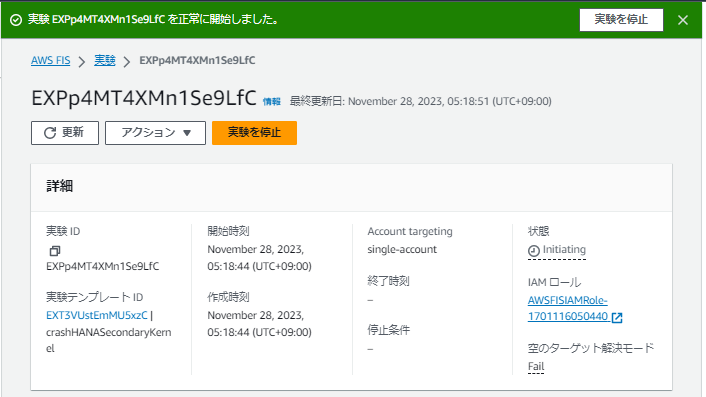
実験後、プライマリのEC2にログインしてcrm statusのコマンド結果を見ると、「Node List」で「prihana」が“Online”、「sechana」が“OFFLINE”に戻っていることが確認できます。
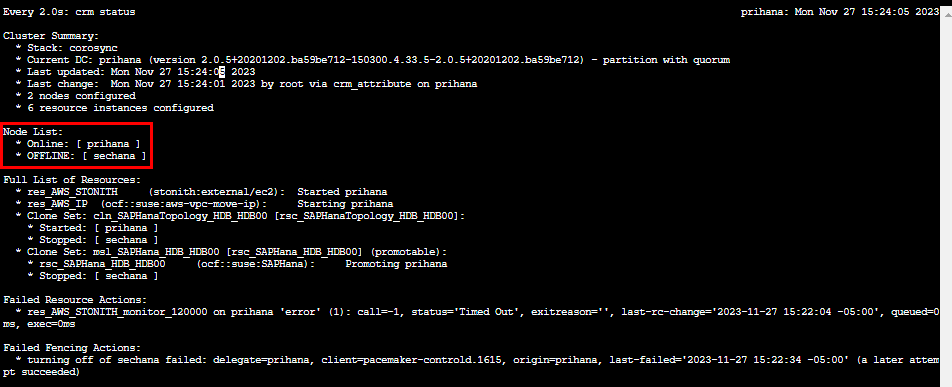
また、プライマリインスタンス上でhdbプロセスが動いていることも確認できます。
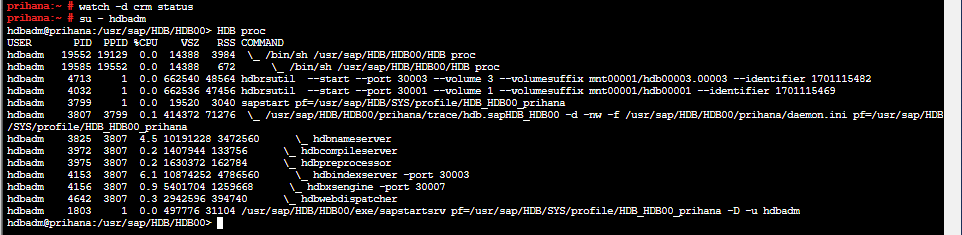
続いて、カーネルクラッシュを起こしたセカンダリのEC2をマネジメントコンソールから起動します。
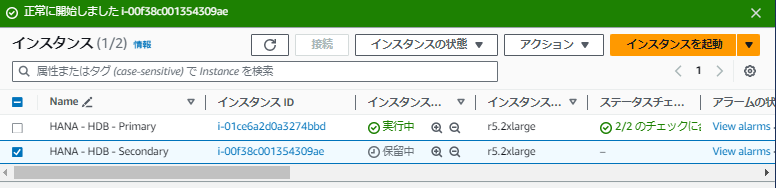
Attributeを確認するとプライマリ、セカンダリが設定されていることが確認できます。

ラボ1.3 サブネットレベルのネットワーク中断
ラボ1.3では、プライマリのEC2が配置されているサブネットに障害を発生させてセカンダリが昇格できるかを確認します。
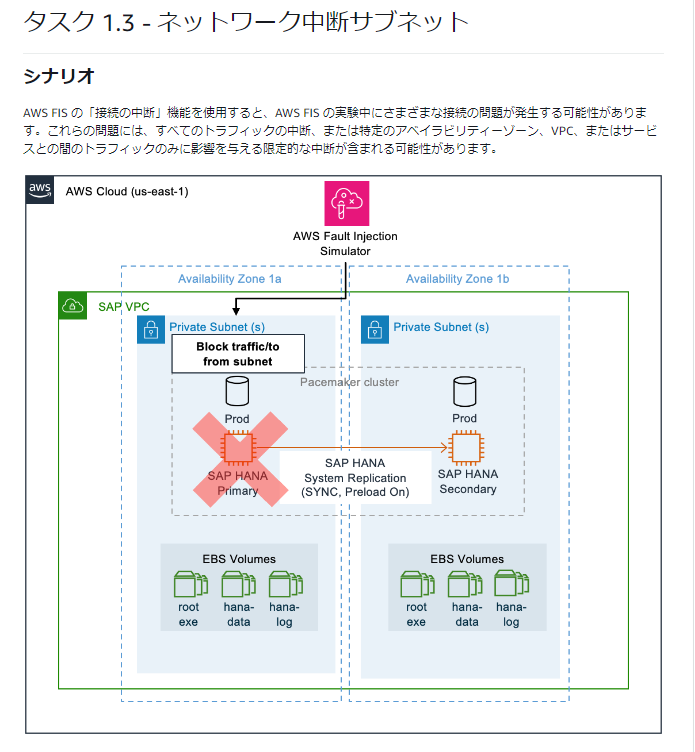
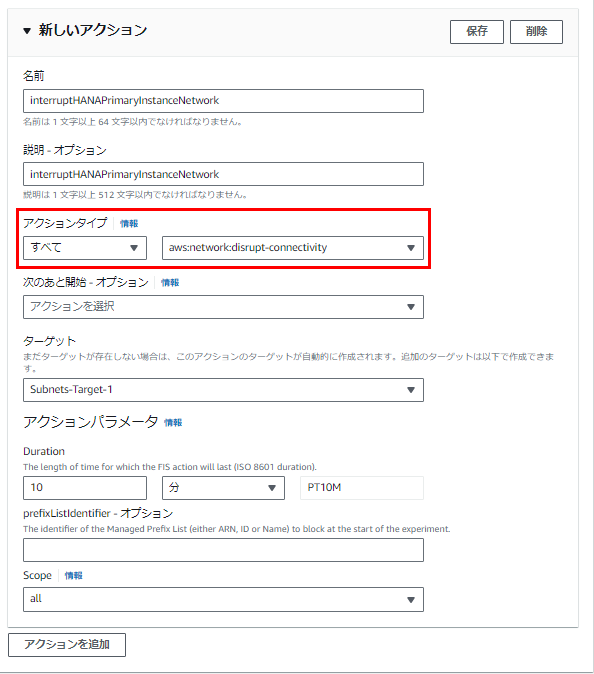
ラボ1.2と同様にAWS FISの実験を作成していきます。
サブネットの障害は「aws:network:disrupt-connectivity」です。
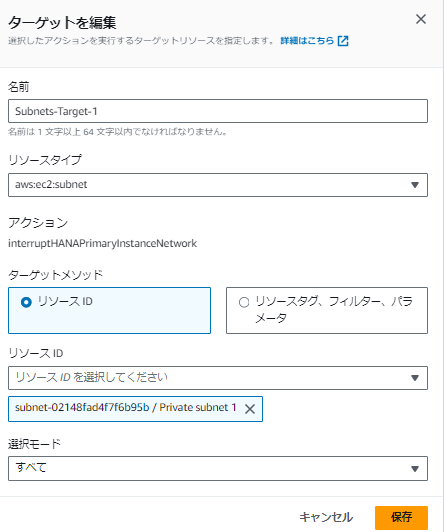
ターゲットでプライマリのEC2が所属するサブネットを選択します。
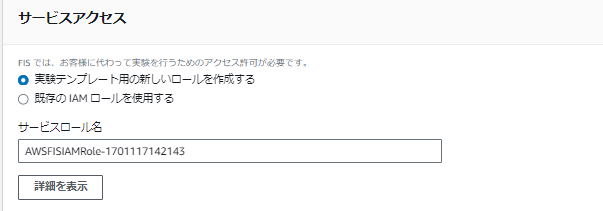
ロールはラボ1.2と同様に新規、デフォルト名称で作成します。
実験テンプレートが作成されたら実行します。
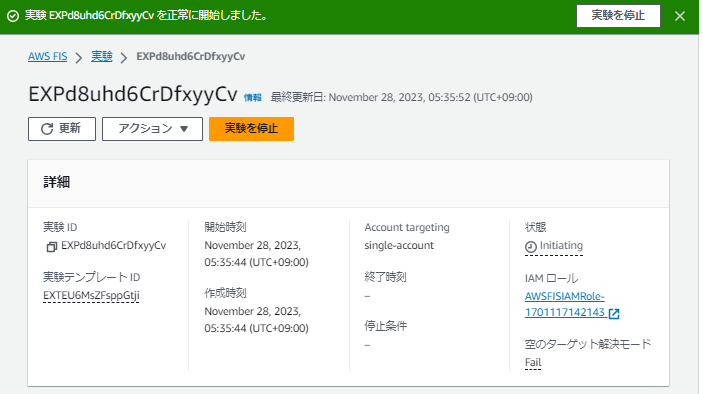
切り替えが終わるとセカンダリのEC2側でHDBのプロセスが起動していることが分かります。
実験を停止します。
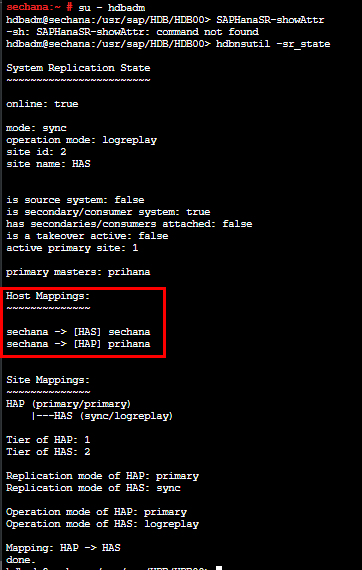
プライマリ、セカンダリが元の状態になっていることが確認できます。
以上で終了です。
ワークショップを得ての考察
今回のワークショップでは、AWS上にWell Architected Framework SAP Lensに準拠し作成された疑似SAP基幹システムに対して、よくあるケースの障害を意図的に起こしレジリエンスがあるどうかを確認しました。
重要なのは、定期的にこういった疑似障害(カオスエンジニアリング)を起こして、自分達が使用しているシステムは果たして障害が起きた時に復旧できるだろうか、その復旧手法は確立できているだろうか、といった運用の見直しが必要であるということです。また、そうした運用を助ける手段を予め準備しておくことも必要です。その一つが、今回のワークショップで使用したAWS FISで障害のケースをテンプレート化(実験)しておくことです。
また、今回は復旧方法についてのワークショップはありませんでしたが、Sytems Manager等のマネージドサービスを利用してコマンドで実施する仕組みを作っておくことなども有効です。それらの運用環境を整備しておくことで、障害時の自動復旧も可能になると考えます。
AWS FISは、ローンチ当初はシナリオケースが少なかった為、カオスエンジニアリングのツールとして使用できるか不確実でした。今回の体験では、テストシナリオが追加されていて、今後、障害テストのツール候補となりうる充分な品質になっていました。ぜひ導入を検討してはいかがでしょうか?
富士ソフトのAWS関連サービスについて、詳しくはこちら
アマゾンウェブサービス(AWS)




