
はじめに
AWS Ambassadorの安斎です。3年ぶりに米国 ラスベガスで開催されているAWS re:Inventに参加しています!
AWS re:InventとはAWSのクラウドコンピューティングのエキスパートから直接技術や事例を学ぶことができるAWS 最大のラーニングカンファレンスです。
前回は、Keynoteで発表されたAnalytics関連のアップデートについてご紹介しました。本レポートでは、2日目に聴講したデータガバナンスに関するセッションをご紹介します。
Enabling agility with data governance on AWS
11月29日 15:30〜16:30
Jason Berkowitz, Sr. Manager, AWS Lake Formation, Amazon Web Services, Inc.
shihas vamanjoor, Vice President, Enterprise Data Platforms, Prudential Financial
タイトルを日本語に訳すと「AWS上のデータガバナンスで俊敏性を実現するには!」となり、とても興味を惹かれるセッションでした。
データガバナンスとは、エンドツーエンドのプロセスを通じてデータを管理し、その正確性と完全性を確保し、必要な人が確実にアクセスできるようにするプロセスのことです。蓄積されたデータの解析結果を元に課題解決や意思決定を行うデータドリブンを始めるには、データガバナンスが必要不可欠です。
ビジネスの85%はデータドリブンを必要としていますが、実際に成功しているのはたった37%だそうです。少ないですね

まず、データガバナンスを始めるためのライフサイクルの紹介がありました。
データガバナンスにおいては、データを提供する側(Producers)とデータを利用する側(Consumers)が登場します。データガバナンスのプロセスでは、データを分類してプロファイルし、洞察を得やすい質の高いデータとしたものをセキュアに暗号化して保存し、カタログ化して共有します。その後、最適化やアクセスコントロールを行い、キュレーションや統合したものを暗号化して保存します。この一連の流れを継続的に行う必要があります。
つまり、データ提供者とデータ利用者の間でデータのやり取りをする時には適切なアクセスコントロ―ルを設定し、安全にデータを管理しながらキュレーションする必要があるということです。
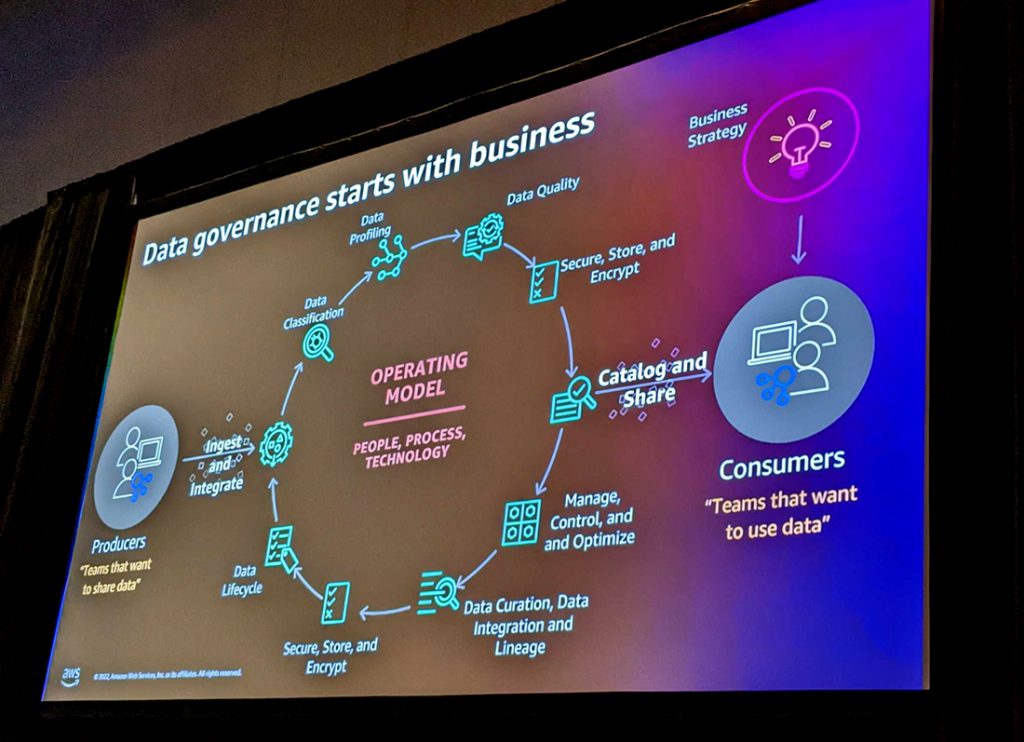
取得したデータのガバナンスを自動化するには、データパイプラインを作成し、データの品質やパフォーマンス、再利用に不確実性が無いようにして規則を遵守することが大切だと話されていました。データガバナンスのためのライフサイクルを一貫性と規則性を持たせて毎回手動で実施するにはコストがかかってしまうので、自動化することが大切ですね!

一連の流れを図にすると以下のようになります。
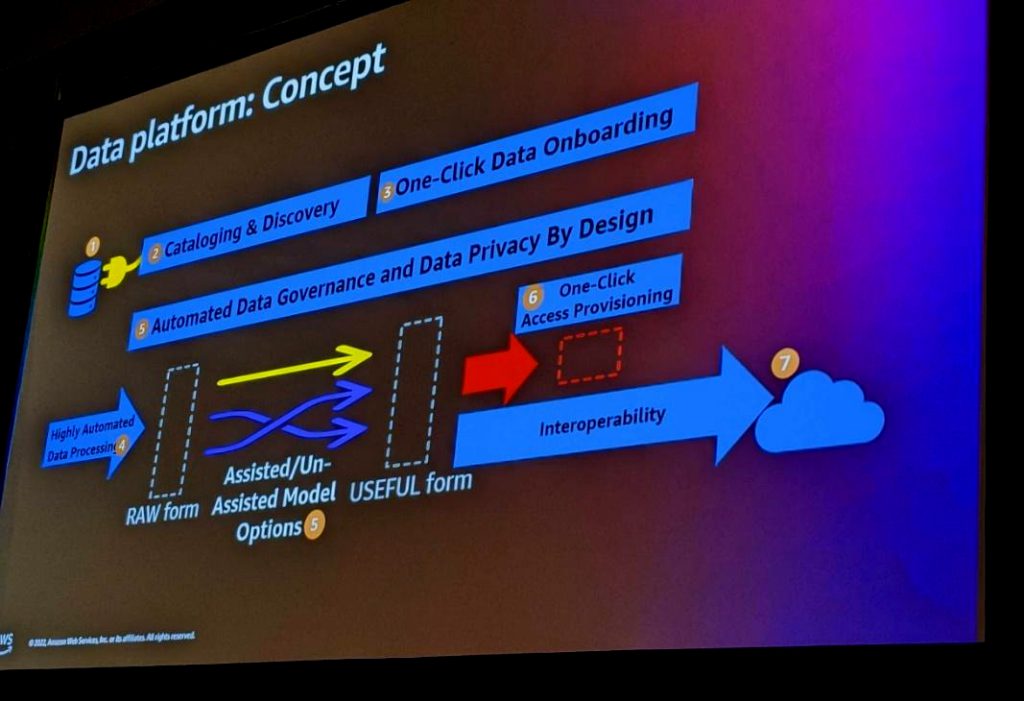
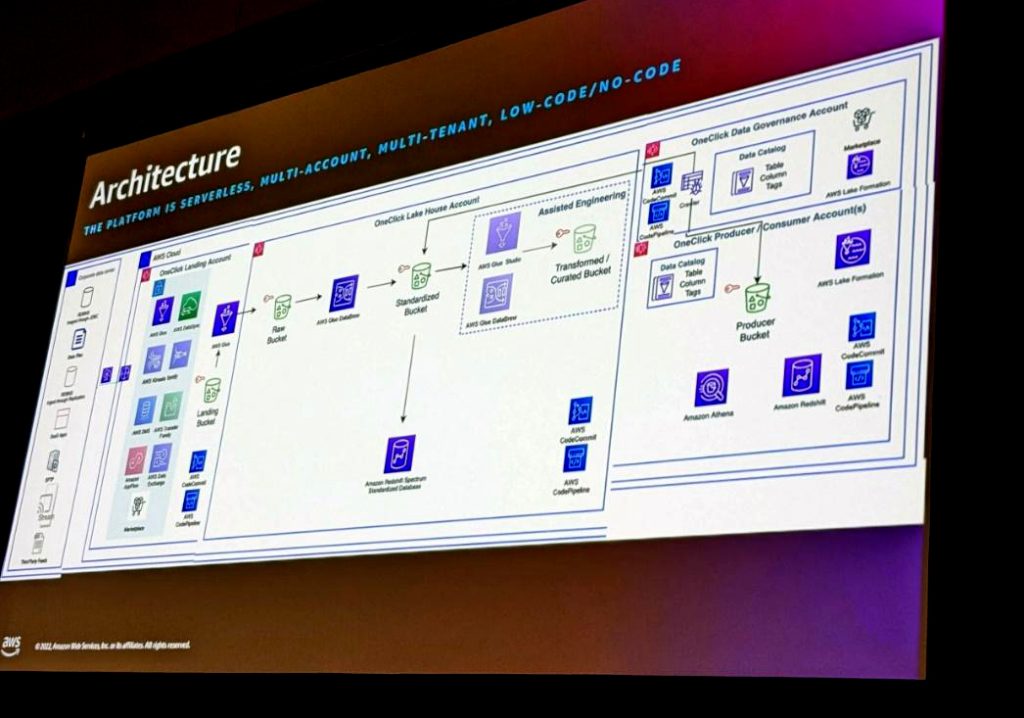
データガバナンスの自動化も含めたアーキテクチャのサンプル紹介もありました。
このアーキテクチャはサーバレスで実現していること、各フェーズでアカウントを分けて統制を取っていることがポイントです。
またマルチテナントでコードは最小限に抑えています。個人的には、データローディングから分析、統制、ユーザ用とアカウントを分離することで統制を取っているところが一番良いと感じました。
エンドユーザ側の不用意なオペレーションミスも影響範囲が小さく抑えられますし、各フェーズが分解されていることでアカウント毎の目的が明確化されやすいと思いました。
さらに、ETL処理をマネージドサービスに任せることで、インフラの管理コストも削減できますね!
まとめ
データガバナンスの必要性に関して、最初からうまく作成できるわけではないのでスモールスタートで始めて、少しずつ統制を大きくしていきましょうという話に感銘を受けました。データガバナンスのライフサイクルが確立できたら終わりではなくて、データ分析を行う限りはそのサイクルで継続的にデータを運用していくことが重要だと学びました。
現地参加では英語でのセッション聴講になるので難易度が高いのですが、AWSの知識を持っていることでシステム構成図やフロー図を見て理解できる部分もあり、改めてAWSを学んでいてよかったと感じました。
AWSは国境を越える!

富士ソフトのAWS関連サービスについて、詳しくはこちら
アマゾンウェブサービス(AWS)




